In today’s technology-driven business environment, your organization’s data is extremely vital and crucial. Your access patterns, data availability & security, is utmost important to your business success. Any disruption to secure, recover, and retrieve your data can prove expensive &/or inferior. As per the Gartner study, only a small percentage of companies have fully recovered from a huge data loss. Though you’ll hopefully never encounter one, wide-spread disasters happen quite frequently. You might not be able to forecast every aspect of a possible disaster, but you, as a business owner/organization can check and outline the principles on
“Are we ready for any kind of outage with the right cost-effective DR solution”
If we build the systems with AWS high resilient architecture designs, we don’t need to worry much about the backup and recovery solutions/downtime/data loss/revenue loss etc in case of natural or human induced disaster.
Though we have business continuity by implementing AWS DR solutions, it is imperative to pay utmost attention to the business requirement and the cost associated with it (Some DR solutions can help you save time and money up to 90%). The intensity of disaster varies from time to time & region to region, and no two disasters are the same. A well-planned DR design is an integral part to come up with the most acceptable DR solution by introspecting your environment viz..
- Have you defined your Recovery objectives such as RPO & RTO?
- Have you identified critical systems and the order in which they should be recovered?
- Have you established a DR strategy?
- Have you understood the need for partial vs. full system recovery?
- Have you tested your DR plan?
- Have you come up with the problem identification and its impact if not addressed?
- Is a review mechanism in place?
- Are you keeping track of ongoing issues & the solution roadmap?
- Are you prepared to improve your plan for future DR scenarios?
This blog mainly addresses the DR solution for SMBs, which is the most powerful, cost-effective, and quick recovery solution of critical databases/elements of your application where the acceptable RPO is 12 hours and RTO is 4 hours.
AWS introduced Pilot Light DR concept around 2013-14.
‘Pilot light’ is a minimal version of your IT environment, running in the cloud, that can be immediately spun up in case of an emergency. You can quickly build around that core to fully restore your application.
With Pilot Light, only critical systems are backed up like RDS and other non-critical systems configurations viz. CloudFormation, Snapshots, AMIs, etc. are made to ensure they can be brought up in need of recovery. This solution allows the rapid provision of a working, fully-scaled production environment. The AWS resources built around the dataset will be in the stopped state when not in use, which becomes the prime factor for cost savings.
For less critical systems, you can ensure that you have any installation packages and configuration information available in AWS, e.g., in the form of an EBS snapshot. This will speed up the application server setup, because you can quickly create multiple volumes in multiple Availability Zones, to attach to EC2 instances. You can then install and configure accordingly.
It is not always ‘All or None’ law.
When you do a deep dive analysis on cloud expenses, you will notice that most of the amount spent was on “what you think you need” rather than “what you need.”

The Pilot Light option allows you to recover your systems much more quickly than the Backup and Restore approach since you’ll already have a core piece of your environment ready to roll at all times.
From a DR perspective, when you use Pilot Light.
- Choose what needs to failover, as somethings still be working
- Choose the essential things to recover than others
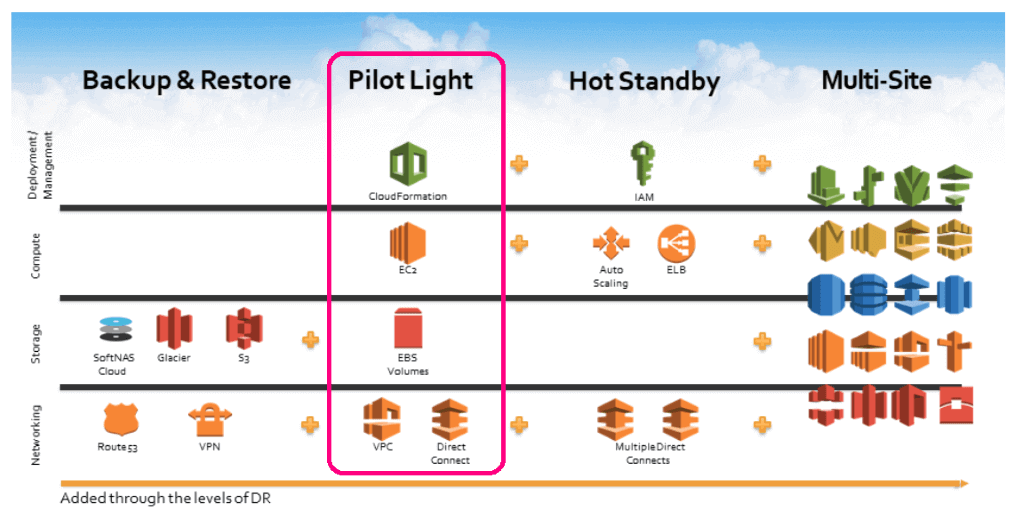
List of AWS services used in the implementation of Pilot Light
You can implement this cost-effective Pilot Light DR solution with just 5 AWS services viz. CloudFormation, EC2, EBS, VPC & Direct Connect.
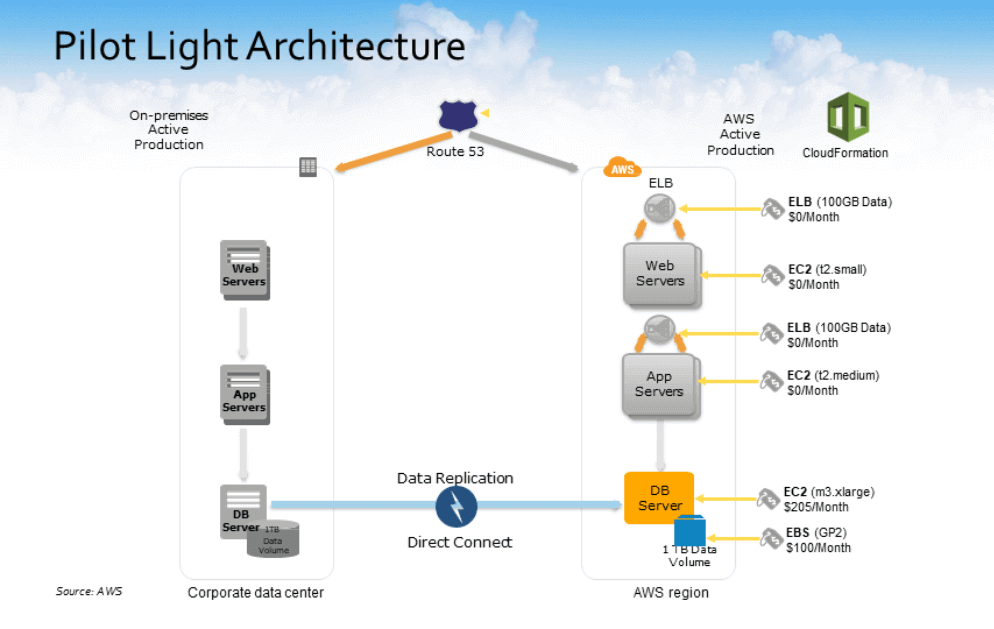
Pilot Light Architecture
Elements typically include
- Replication of data in the cloud
- Pre-configured servers ready to be launched at a moment’s notice
- Storage of installation packages or configuration information
- Setting up additional database instances for data resiliency.
When the time comes for recovery
- Fire up your pre-configured cloud servers quickly
- Route your traffic to those servers
- Scale them up as necessary
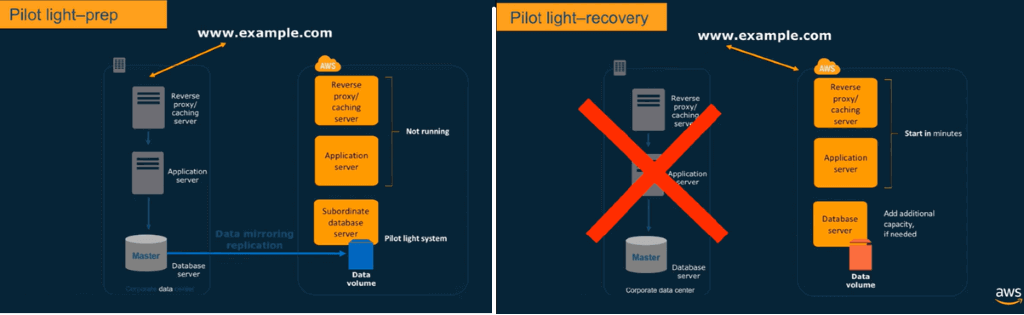
Scenario
You have your own data center, and Amazon Route53 points to your on-premise system.
You have a database instance in the AWS cloud, where you replicate data from your on-premise system. You have 2 servers that represent your web tier and your application tier but they are not on or running yet. If the primary system fails, you grow your database server to the size that it needs to be taken on production data traffic, then turn on the webserver & application server and point Amazon Route53 to your new servers. This entire process can happen in minutes.
Key Takeaways
- Pilot Light infrastructure depends on your RTO.
- Uses fewer 24/7 resources, hence it is a cost-effective solution
- By identifying your business-critical systems/applications, you can fully duplicate them on AWS and have them always on.
- You can scale higher or lower, based on your current needs
- In the preparatory phase, it enables the replication of all critical data to AWS and prepares all required resources viz. AMI, Network settings, Load Balancing for automatic restart.
- In case of disaster, Pilot Light automatically brings up resources around the replicated core data set & scale the system as needed to handle current production traffic and of course switches over to the new system by adjusting DNS records to point to AWS.
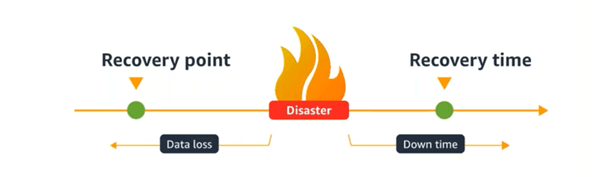
- RTO (Recovery Time Objective) is the maximum acceptable length of time that your application can be offline before seriously impacting your business operations.
- RPO (Recovery Point objective) is the maximum acceptable length of time during which data might be lost from your application due to a major incident.