

How much money are you spending on your data extraction processes? Research shows that enterprises spend over $30 billion manually extracting documents’ data. The simplistic rule-based Optical Character Recognition (OCR) has been here for over a decade. It captures and extracts data from scanned copies or PDFs. Though it has done wonders, is it solving the evolving business challenges? The answer is no. Here is where intelligent data extraction comes into the picture.
Intelligent data extraction uses the advanced capabilities of AI to extract data from documents from multiple sources and in various formats. Gartner reports that intelligent document processing (IDP) can save 25,000 hours of rework for the finance team caused by human error costing $878,000 annually for an enterprise with 40 members accounting team. Here are the limitations of OCR, which makes intelligent data extraction a better option.
Limitations of OCR
The initial purpose of OCR was to translate written text to speech for the visually challenged. A few more limitations are as follows.
- Highly input dependent
The processing efficiency depends on the quality of the input picture. Also, the precision decreases when the character height is less than 20 pixels.
- Rule-based
The engine is programmed to extract the correct data. It uses templates and rules to process the document. Thus, it cannot handle unstructured data.
- Needs more automation
For every different format document, it requires a rule for each data field. As it depends on rules and templates to process the document, automating it further has very few opportunities. Adding more rules will need additional training data and resources. Thus making it a complex task to do.
- Costly
To improve the accuracy, it requires additional rules and templates. This does not guarantee high-quality outcomes, as the result still depends on the picture quality.
- Inefficient in handling different formats
OCR provides accurate results when documents deviate little from the template or the programmed rules. The more the deviation, the more difficult it becomes to process the data. Thus, it cannot manage different formats.
Manual processing Vs. Optical Character Recognition Vs. Intelligent Data Extraction
| Features | Manual Processing | Optical Character Recognition (OCR) | Intelligent data extraction or Intelligent Document Processing (IDP) |
| Accuracy | 70% – 80% | 80% – 90% | >99.5% |
| Turn-around time | >15 minutes | 2-5 minutes | >60 secs |
| Human intervention | 100% | Requires for data processing | Very less |
| Data interpretation | | | |
| Self-learning ability | | | |
| Different layouts formation | | | |
| Complex document processing ability | | |
How Intelligent Data Extraction works?
Intelligent Data Extraction works like humans read and recognize text patterns and characters. It takes an unconventional approach through a series of processes to improve image quality and extract accurate data. Furthermore, manual data processing is time-consuming and prone to human error.
Intelligent data extraction follows deep learning and ML-based OCR-hybrid data extraction techniques that needs supervised/unsupervised learning to train their models. Also, the accuracy rate and confidence score determines the efficiency of these models. The accuracy gets better as you process more and more documents. A simple OCR correction approach, along with context-based NLP, improves data accuracy and quality. SAXON’s Digitalclerx member, Emma takes a similar data extraction approach with the Machine Learning (ML) and template-based OCR. She can learn and recognize various formats of data to provide the best accuracy and results.
Intelligent data extraction involves the following processes.
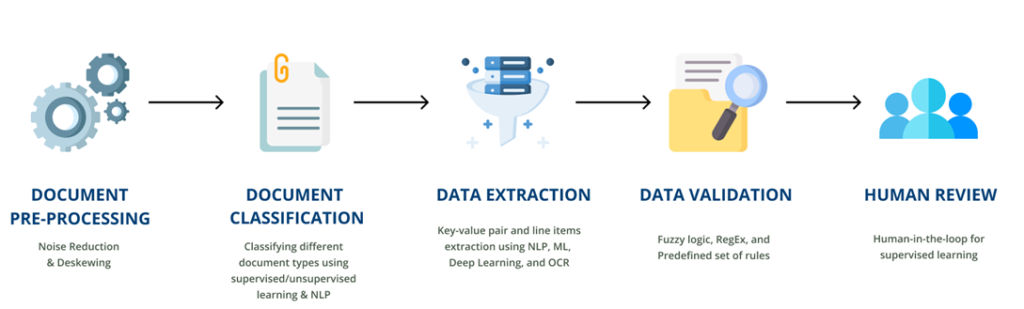
- Document pre-processing
The image quality must be reliable for accurate data extraction. The better the image quality, the better the data. Thus this is the image enhancement phase. During preprocessing, the OCR engine automatically searches for and fixes errors. Hence, these methods are commonly used to enhance photographs or scanned documents:
- De-skew – The term “de-skew” refers to fixing the image or the scanned document
- Binarization – changing colored images to black and white for better data extraction.
- Classification – Zonal OCR identifies the data’s columns, rows, sections, titles, paragraphs, and tables.
- Normalization – Normalization reduces noise by bringing each pixel’s intensity closer to the average intensity of its nearby pixels’.
- Document classification
- Identify the format like JPG, PNG, PDF, TIFF, etc.,
- Identify the structure – The OCR solution attempts to distinguish between structured, semi-structured, and unstructured documents. Structured documents have a fixed template and layout, whereas semi-structured documents have an undefined structure. Invoices are a great example of semi-structured documents because the vendor’s address can vary between invoices. So, the document processing solution should have some contextual understanding of the data and document to make sense of these values.
- Identify the document type, whether the ingested document is an invoice, bank statement, t12 statement, shipping label, or anything else. The data already fed into the IDP solution aids in successfully identifying a document type and queueing it for data extraction.
- Character Identification
This is a crucial stage. The image or document is divided into sections, tables, subsections, or zones. The key identifiers or characters within them are identified after separation. It uses two methods in this step.
- Matrix matching – compares individual characters to a database of character matrices. OCR engine compares pixel by pixel to find the match.
- Feature recognition – identifies text patterns and character features in photographs. It compares A character’s size, height, form, lines, and structure with the available collection.
- Data validation
This step improves data extraction accuracy for the best results. It is critical for detecting errors in the extracted data. Within the document, specific data validation rules are applied so that any inaccuracies can be detected and flagged for correction.
For Example – In an invoice, the ‘total amount payable’ should be the sum of the subtotal and the ‘tax payable.’ If there is a difference between two invoices, the invoice is flagged and held for review.
- Human in the loop
After data validation, the human in the loop reviews any flagged document. The more documents are processed and reviewed, the more accurate the data extraction model becomes. This is especially useful in supervised learning and improving the model’s accuracy. Once the data is extracted and cleaned, the software pushes it to the database or exports it in various formats. In addition, documents can be converted into JSON, XML, PDF, and other formats using IDP workflows.
Benefits of Intelligent Data Extraction:
Intelligent Data Extraction improves the efficiency of your organization by harvesting data in real time, delivering it to the lead systems, and quickly providing critical information to the end user.
- Reduces operating expenses
Traditional methods are expensive as it is labor intensive and requires resources to store and manage physical documents. Intelligent document processing avoids all the tedious tasks with its automated workflows.
- Single point of capture
Intelligent data capture learns to recognize different types of documents at the single point of capture and the source of crucial data. Efficiency continues to improve as it handles more and more data.
- Improves organizational synergy
Intelligent data capture facilitates dynamic engagement through a shared data set without requiring co-location. Thus, boosting the accessibility of data and the synergy between teams and departments.
- Enhanced security
Content routing provides limited access to those who examine and verify data. It encrypts input data to avoid data breaches and loss by securely recording and storing it in a unified location.
- Better compliance
It provides higher-quality data with error-free categorization and characterization of data. In addition, the data is connected to an audit trail, which ensures compliance standards are followed.
- Streamlined Process
It uses a single platform to serve department-specific users and procedures. Thus, it streamlines the data capture, validation, and routing processes.
- Increased productivity
Automated workflows avoid tedious tasks and hence provide error-free data. Hence, you can focus on other priority tasks when intelligent data capture can do the work for you.
Intelligent document processing or data extraction saves over 50% of processing time and 80% of processing costs. Automation is all you need if you wish to optimize your document processing processes.
SAXON helps organizations to seamlessly integrate automation into their system, improving ROI, cost savings, process cycle times, and overall business performance.
Move up the automation curve with SAXON