

In 2022, storing Big data is not a challenge anymore. Organizations today have a severe hidden gap in how they use their data. This gap arises in how enterprises utilize their unstructured data. This gap, when left unseen, will lead to inefficient cloud usage, missed business opportunities, poor decisions, and a threat to data compliance and governance.
Are you equipped to use your data effectively?
Can an organization be truly data-driven by utilizing just 10-15% of structured data?
Unfortunately, organizations use significantly very fewer data to make business decisions. A truly data-driven organization utilizes 100% of its valuable data. Why should organizations focus on utilizing all of their data? Research shows that data-driven organizations are 23 times more likely to acquire customers, and businesses that use their data were able to increase their profit by 8%.
IDC predicts that by 2025 unstructured data will make up to 80% of all the data enterprises generate. It is rapidly growing at the rate of 55-65% annually. This alarming increase in unstructured data is a warning for enterprises to equip themselves with technologies that can manage and extract insights from unstructured data to make intelligent business decisions and maintain data compliance and governance.
This unstructured data comes from different sources and in different formats like texts, emails, images, PDFs, videos, etc., which adds to the complexity of processing the unstructured data. Usually, we categorize structured data into rows and columns, but unstructured data does not fit into any pre-defined data models. The lack of structure makes arranging highly difficult and may contain redundant duplicates or incorrect values.
Extracting insights from unstructured data is now possible with knowledge mining capabilities. Let’s get into more details.
How can you extract insights from unstructured data?
The Harvard Business Review survey says the need for knowledge mining is snowballing. Currently, 77% are manually processing unstructured data, knowledge mining will soon outpace it.
With knowledge mining, you can bring value to every conversation and transaction.
- It brings out the latent insights covered within structured and unstructured data.
- It uses AI pipelines to discover insights and patterns from any data at scale.
- It speeds up searching for content and not only extracts insights but provides a deeper understanding of the content in your data.
- It helps you craft process models to make intelligent business decisions effectively.
- It uses various pre-trained and custom AI services like computer vision and natural language processing.
- It also provides the ability to include custom Azure ML models.
- It enables users to discover patterns and relationships, including search interfaces, analytics solutions, and other business applications.
Transforming 30 Years of Knowledge into Instant Answers
Benefits of Knowledge mining
There are a plethora of benefits to knowledge mining. You can use it across multiple industries to extract information from any data, avoiding tedious and laborious work and saving money and time for enterprises. Here are a few benefits,
- You can use AI assistants to perform cognitive tasks such as indefinitely comprehending, perceiving, calculating, analyzing, and reasoning and draw valuable inferences and insights from massive amounts of data.
- While pre-trained AI models work well for most use cases, for the scenarios that demand custom models, knowledge mining helps seamlessly stitch the custom models tailored to the needs eliminating time-consuming and expensive organizational tasks.
- It simplifies accessing the latent insights within unstructured data.
- It helps stakeholders find insights from vast data to make better-informed decisions, automate redundant business processes, and identify risks and new business opportunities.
- Organizations can Identify, classify, and protect sensitive information in their unstructured data and maintain high compliance and governance.
How knowledge mining works
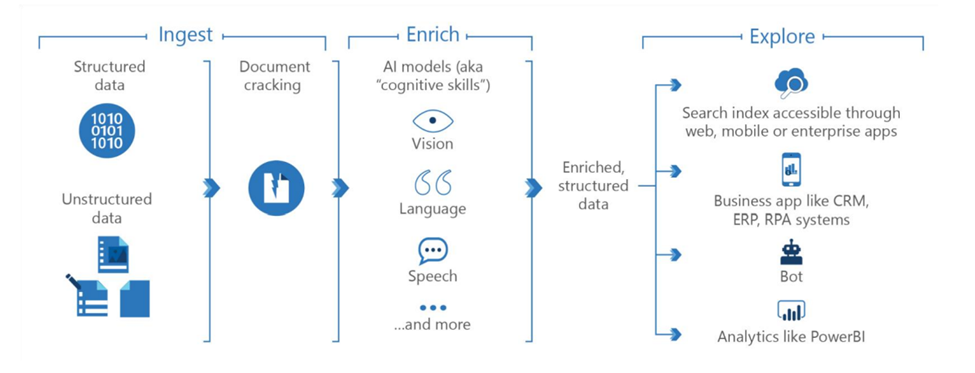
Ingest
This is the first step where we ingest the data. The structured data has a definite model and resides in relational databases. Most of the business’s documents come under unstructured data, including images, videos, audio files, PDFs, word documents, excel spreadsheets, and rich text formats, which has led to the birth of knowledge mining. Unstructured data comes from blob storage, file stores, and many other sources.
In Data ingestion, all the data from different siloed data sources are brought to a centralized data store. The ingested data is given a standard structure in the import process according to the information extracted through document cracking to use enriched documents effectively. Document cracking extracts or creates text content from non-text sources using Optical Character Recognition (OCR).
Enrich
Enrichment steps:
- Each document is enriched with AI models.
- Every enrichment step acts on the raw data and the data already enriched by the previous actions in the pipeline.
- This multiple enrichment helps to build upon powerful insights from the raw unstructured data.
- AI enrichment models can be either pre-trained or custom, and pipelines frequently include both. Most enrichment pipelines start with pre-trained NLP and computer vision AI services to uncover valuable information and build custom models for business requirements.
- Natural language processing interprets sentiment, detects, and translates languages, and extracts words, key phrases, and the names of people, locations, and organizations from written text and speech.
- Computer vision can analyze images and videos to detect and classify faces, landmarks, caption images, transcribe handwriting, or other objects. Custom models for specific industries enhance the capabilities of knowledge mining.
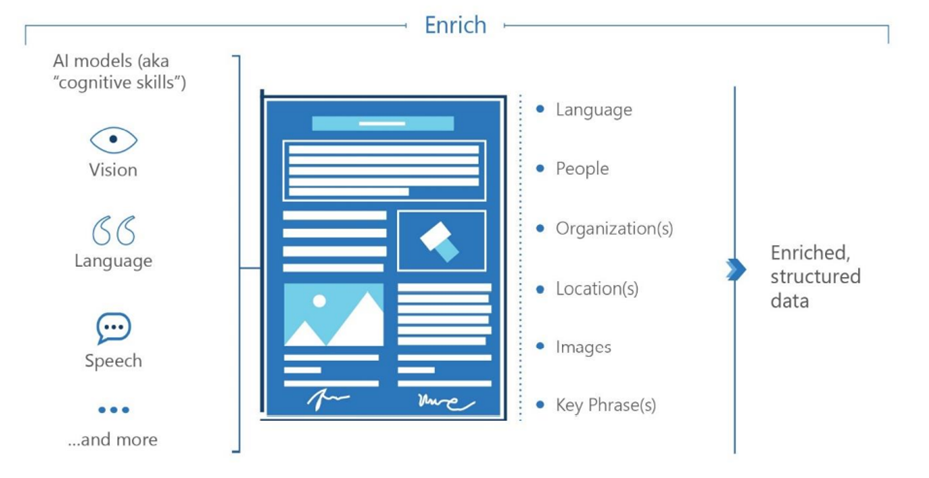
- At the end of the AI document enrichment step, each document is enriched and contains data conforming to the structure defined by the pipeline.
Explore and Analyze
This is the final step of knowledge mining, where the enriched and structured documents are available to explore and analyze. The steps include
- Adding the documents to the search index or writing the storage path
- Review the enriched documents to understand more about the data.
- Make the enriched data available in CRMs or ERP systems.
Exploration is where you can search for relationships by searching for keywords. The analysis involves applying tools like Azure machine learning, Power BI, and Azure Databricks to better understand the enriched data through reports and dashboards, extract actionable insights and perform anomaly detection.
Harvard Business Review says the basis for some of the most significant innovations can be underlying in unstructured data. By adopting knowledge mining, enterprises can unlock the value of their unstructured data and make intelligent business decisions.